nLab para construction
Context
Category theory
Concepts
Universal constructions
Theorems
Extensions
Applications
Contents
Idea
The Para construction is a variety of strictly related functorial constructions that produce a category of parametric morphisms.
In the simplest case, one starts with a monoidal category and builds a category whose morphisms are pairs where is a parameter and is a morphism in .
Such a morphism might be visualised using the graphical language of monoidal categories (below, left). However, this notation does not emphasise the special role played by , which is part of the data of the morphism itself. Parameters and data in machine learning have different semantics; by separating them on two different axes, we obtain a graphical language which is more closely tied to these semantics (below, right).
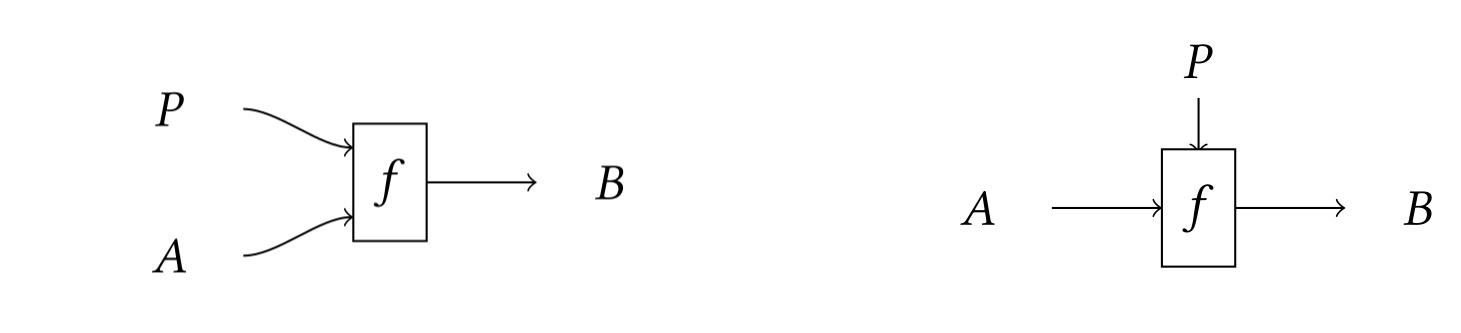
This gives us an intuitive way to compose parameterised maps:
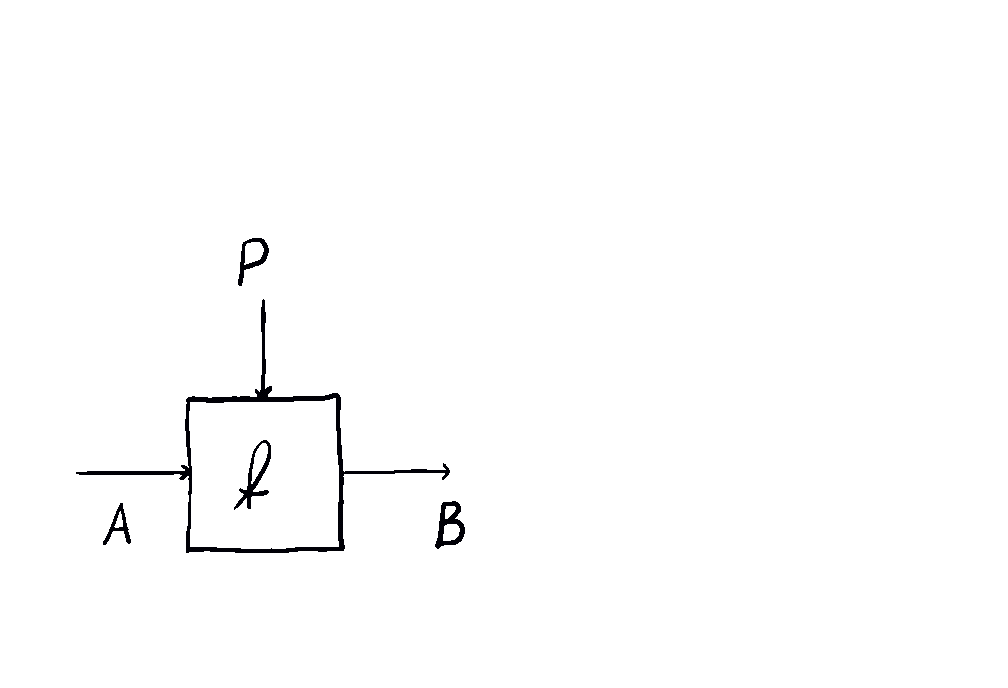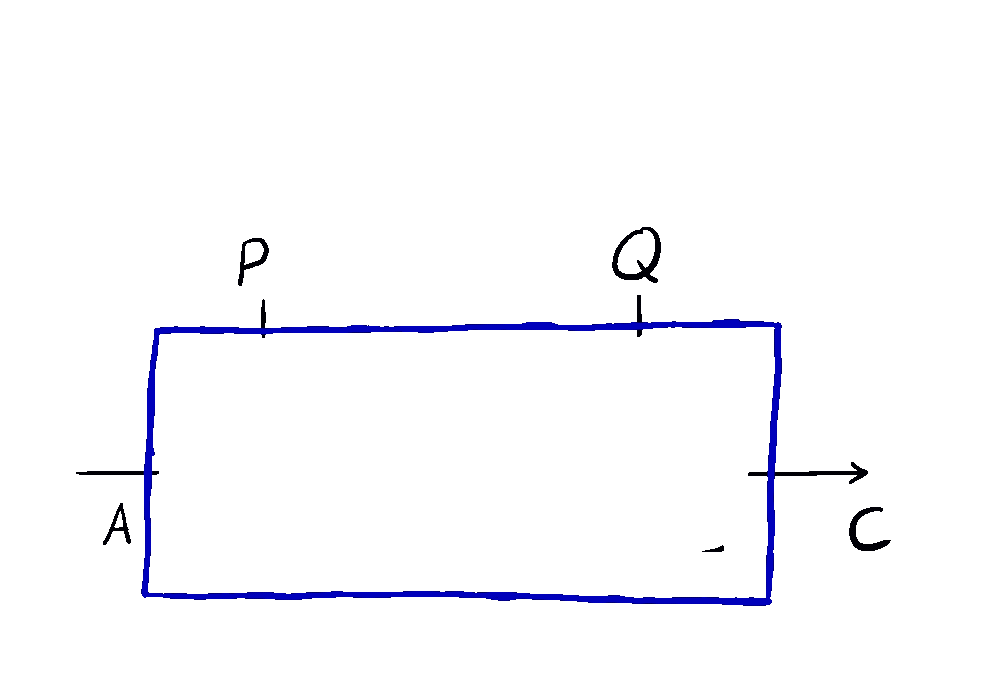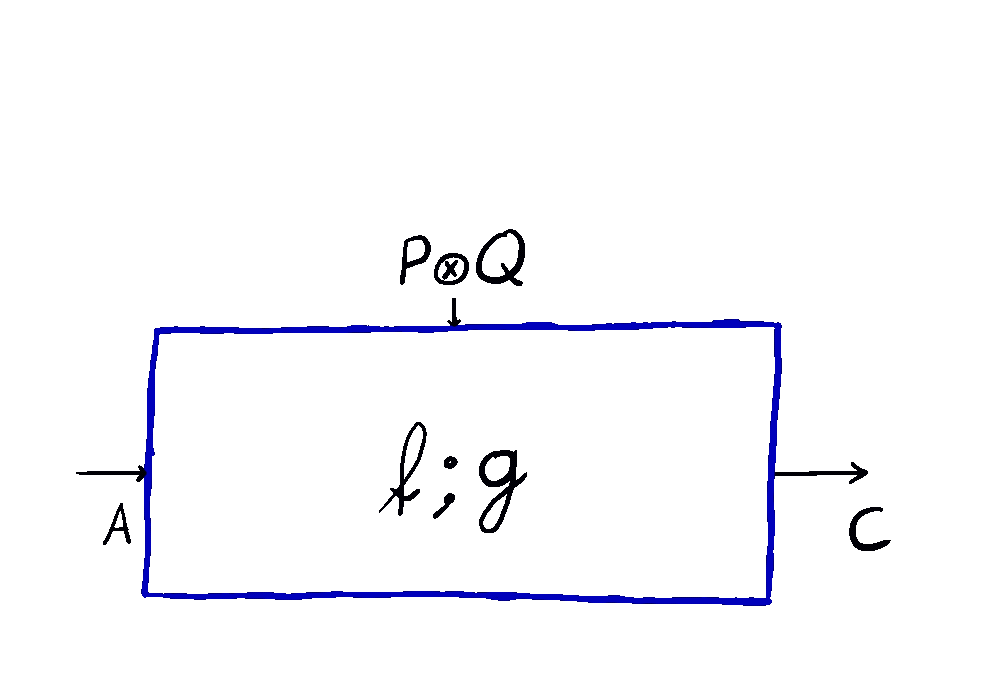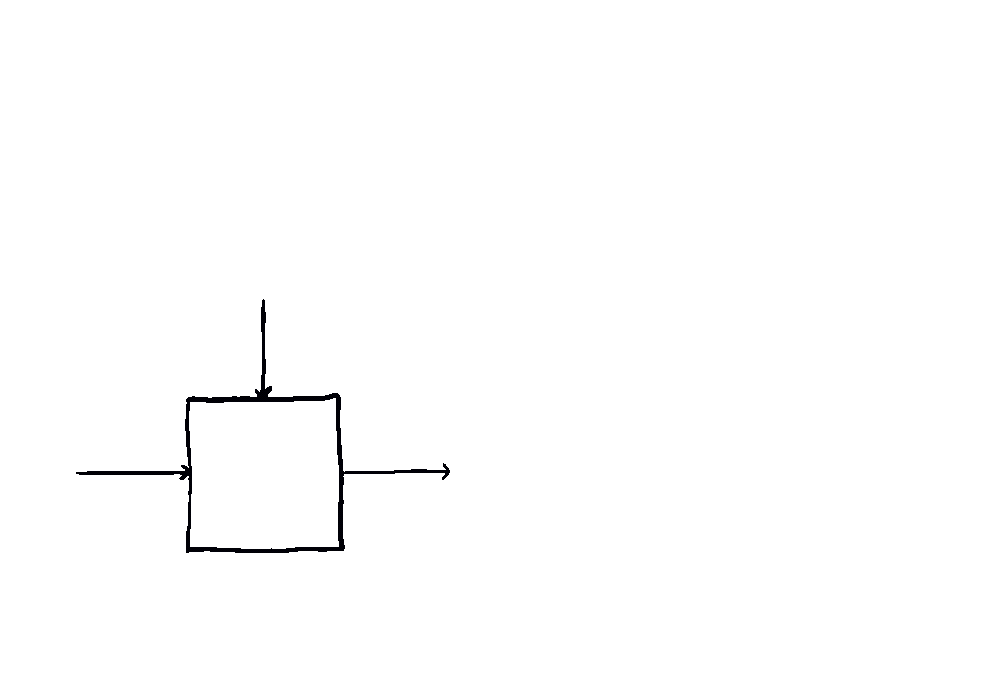
The Para construction is of relevance in categorical cybernetics, since controlled processes such as machine learning models, economic agents and Bayesian reasoners are straightforwardly modeled as parametric processes of some kind.
Indeed, the notation was originally introduced in (Fong, Spivak and Tuyeras 2019), and then successively refined in (Gavranovic 2019) and (Cruttwell et al. 2021) for applications to machine learning. (Capucci et al. 2020) generalized the construction from monoidal categories to actegories, in order to capture examples from other areas of categorical cybernetics. A still further generalization and systematization of the Para construction is being developed by David Jaz Myers and Matteo Capucci, see (Myers 2022) and (Capucci 2023).
Nonetheless, the 1-categorical version of Para already appears e.g. in (Hermida & Tennent 2012), with precursors in (Pavlovic 1997). Also, Baković 2008, Thm. 13.2 introduces Copara (under a different name) in the very general context of actions of bicategories.
Definition
For monoidal categories
Definition
For a monoidal category, is the bicategory given by the following data:
-
Its objects are the objects of .
-
A 1-morphism is a choice of a parameter object and a morphism in of the form
-
A 2-morphism is a morphism in such that the following diagram commutes:
-
Identity morphisms are given by the right unitors:
-
The composite of a map and is given by the animation above. In symbols, this is the -parameterised map defined as
-
The data of associators and unitors for the bicategory, as well as their coherence diagrams, are defined using those of .
If is strict monoidal, then is a 2-category. One can show that if is commutative, then is symmetric monoidal, since commutativity of allows one to exhibit an interchange. It is believe this still holds if is just symmetric, making a symmetric monoidal bicategory.
For actegories
Definition
Let be a monoidal category and let be a right -actegory. Then is a bicategory with the following data:
- Its 0-cells are the objects of .
- A 1-cell is a choice of a parameter object and a morphism
in .
- A 2-cell is a morphism in such that the following commutes:
- Identity morphisms are given by the unitors:
- The composition of a map and is defined as
- The data of associators and unitors for the bicategory, as well as their coherence diagrams, are defined using those of and .
Again, it is folklore that this bicategory is symmetric monoidal when is a symmetric monoidal action, meaning is monoidal, is symmetric and is a symmetric monoidal functor.
Also, this construction is 2-functorial from to .
Dual construction: copara and bipara
Given a left -actegory, one can produce a bicategory of coparametric morphisms by dualizing the above construction in the obvious way. This is known as .
Likewise, given an -biactegory there is a bicategory whose 1-cells are biparametric morphisms , whose composition rule uses the bimodulator of the biactegory.
Generalizations
The Para construction naturally generalizes in five different ways (with the first four described in (Myers 2022)):
(1.) Move from bicategories to double categories (in the weak sense): is usefully thought of as a double category whose tight category is still , whose loose maps are parametric morphisms, and whose squares are reparametrizations that commute suitably:
(2.) Allow for colax actions. This includes comonads (and graded comonads more generally), since they are colax actions of the terminal monoidal category; and applying Para to a comonad yields a double categorical version of the coKleisli category of the comonad.
(3.) Allow for “dependent parameters”, i.e. for situation in which the parameter of a parametric morphism actually depends on , thus allowing for of the form (notation is suggestive). This makes double categories such as instances of the Para construction (where the left leg encodes the parameter dependency and the right leg is the parametric morphism itself).
(4.) Have the construction take place in complete 2-categories, as opposed to . This allows to describe Para for structured categories and to apply it to different 2-categorical structures (e.g. indexed categories).
(5.) Internal vs. external parameterisation: given a -actegory , the Para construction describes parameterisation which is internal to the category . For instance, given an action on the category Vect, a morphism is a linear map. But often we are interested in morphisms linear only in one variable, for instance, a function . In such cases we’re interested in external parameterisation, one which is captured by being an object of , instead of . A unified perspective on these two approaches is that of a locally graded category.
In categorical cybernetics
Para has been developed to model effectively the compositional structure of controlled processes, such as those involving agents. The examples better developed are in deep learning and game theory, see (Capucci et al. 2020).
The idea that agents are parametric functions is quite old. In fact, agents take in an input and produce an output . However, they have additional inputs/outputs not available to the “outside world”, i.e. not part of their composition interface. These can be the weights (or parameters) of a neural network (or a more general ML model), the strategies of a player in an economic game, the control signal of a controlled ODE or a Markov decision process.
Thus agents are naturally modelled as parametric morphisms.
Examples
-
The Cayley graph of a monoid action (together with its category structure) is a low-dimensional example of a Para construction for actegories.
-
When the base category is set to be the category of optics, then recovers the category of neural networks defined in (Capucci et al. 2020).
-
The “monoidal indeterminates” construction of Hermida and Tennent is a Para construction for actegories. Hermida and Tennent consider a symmetric monoidal functor (hence: a symmetric monoidal action of on ) and provide a symmetric monoidal bicategory and ordinary monoidal category . The morphisms in are pairs where is in and in .
-
If we quotient to get a 1-category by equating connecting components of 1-cells, this is a semicocartesian monoidal category. In fact it is the semicocartesian reflection of . (See (Hermida and Tennent, Corollary 2.13).) Similarly, quotienting gives the semicartesian reflection of .
-
In particular, if we start from the category of finite dimensional Hilbert spaces and isometries, the 1-cells of are Stinespring dilations of quantum channels, and the quotiented 1-category is equivalent to the category of quantum channels (see (Huot and Staton 2018)).
Related concepts
References
The Para construction first appears (though not under that name) in:
-
Claudio Hermida, Robert Tennent. Monoidal indeterminates and categories of possible worlds. Theoretical Computer Science vol 430. 2012. Preliminary version in MFPS 2009. doi:j.tcs.2012.01.001
-
Duško Pavlović, Categorical logic of names and abstraction in action calculi. Math. Structures Comput. Sci. 7 (6) (1997) 619–637. pdf
-
Igor Baković, Bigroupoid 2-torsors. Dissertation, LMU München: Faculty of Mathematics, Computer Science and Statistics, (pdf)
The terminology “Para construction” first appears in:
- Brendan Fong, David Spivak, Rémy Tuyéras, Backprop as Functor: A compositional perspective on supervised learning, 34th Annual ACM/IEEE Symposium on Logic in Computer Science (LICS) 2019, pp. 1-13, 2019. (arXiv:1711.10455, LICS’19)
It has then be developed for the purposes of machine learning in:
-
Bruno Gavranović, Compositional Deep Learning [arXiv:1907.08292]
-
G.S.H. Cruttwell?, Bruno Gavranović, Neil Ghani, Paul Wilson, Fabio Zanasi, Categorical Foundations of Gradient-Based Learning, (arXiv:2103.01931)
-
G.S.H. Cruttwell?, Bruno Gavranović, Neil Ghani, Paul Wilson, Fabio Zanasi, Deep Learning for Parametric Lenses, (arXiv:2404.00408)
and generalized further to actegories for the purposes of categorical cybernetics in:
- Matteo Capucci, Bruno Gavranović, Jules Hedges, Eigil Fjeldgren Rischel, Towards Foundations of Categorical Cybernetics, (arXiv:2015.06332)
The generalization of the Para construction being developed by David Jaz Myers and Matteo Capucci is expounded in the following talks:
-
David Jaz Myers, The Para construction as a distributive law, talk at the Virtual Double Categories Workshop (2022) [slides, video]
-
Matteo Capucci, Constructing triple categories of cybernetic processes [slides, video]
-
Matteo Capucci, Para Construction as a Wreath Product, talk at CQTS (Jan 2024) [slides: pdf]
A view on quantum channels via CoPara:
- Mathieu Huot, Sam Staton, Universal properties in quantum theory (QPL 2018) (pdf).
Last revised on October 15, 2024 at 21:29:54. See the history of this page for a list of all contributions to it.